我用ChatGPT设计了一颗芯片
过去一年多以来,ChatGPT引发的AI浪潮席卷全球。最近,本文作者也通过与 OpenAI 的 GPT-4 对话合作,实现了一个拥有 8 位微架构设计,其每个组件和每个信号都是由 GPT-4 的作者创建的。我们甚至在测试过程中发现 GPT-4 错误后对其进行了修补,并提供了对 ISA 本身设计的见解。
今年早一点的时候,我(指代本文作者)正在纽约大学从事博士后工作,其中之一是探索Verilog 大型语言模型的使用。我们对使用 ChatGPT 等 LLM 来设计硬件的各种不同应用程序进行了基准测试,包括规范解释、设计以及错误检测和修复。我们是这样的领域的先行者之一,早在 2020 年就开始使用 GPT-2 和 Verilog。
我立即对上述帖子产生了兴趣,但由于实际流片的成本过高,我们从始至终使用 FPGA 和模拟。但是,模拟与现实之间总是存在差距,因此表明LLM和人工智能确实可以生产芯片可能对我们的研究领域来说是一个福音。我们能否使用免费流片的Tiny Tapeout 作为实现此目的的工具,并使用LLM不仅编写 Verilog,还为真正的芯片设计 Verilog?
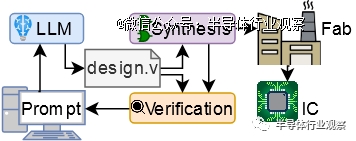
我与我的导师和其他几位博士生进行了交谈,我们集思广益了一些想法。Tiny Tapeout 非常小,只有 1000 个标准单元左右,这在某种程度上预示着设计会受到很大限制,但我们都十分喜爱这个想法,特别是因为似乎还没有人做到过,所以如果我们行动迅速,我们可能会能做到世界*!
所以,我们决定去做。但现在,还有很多其他事情需要仔细考虑。鉴于设计空间如此之小,我们该提交什么?还有别的问题。我们从我们自己之前的工作中知道,LLM可以编写像 Verilog 这样的硬件设计语言,但他们只是不太擅长,与 Python 等更流行的语言相比,语法或逻辑错误的发生率要高得多,这就是为什么我我的团队已经为 Verilog 制作了自己的LLM的原因。
因此,我们应该决定,如果我们确实想使用LLM来制造芯片,(1)我们该使用哪个LLM?(2)我们该给它多大的帮助?(3)我们该尝试什么prompting strategy?
然后我们想出了两种方法。*种方法是尝试让LLM在一种反馈循环中完成所有事情,从而为LLM提供一个规范,然后为该设计生成设计和测试。然后,人类将在模拟器 (iVerilog) 中运行测试和设计,然后将任何错误返回给LLM。
然而,我们从经验中知道,LLM有时也相当愚蠢,并且可能会陷入循环,他们都以为自己正在处理问题或改进输出,而实际上他们只是迭代相同的数据。因此我们推测有时我们在大多数情况下要回馈“人类援助”。
在硬件流片方面,我们的目标是 Tiny Tapeout 3,它将基于 Skywater 130nm。它有一些限制:前面提到的 1000 个标准单元,以及只有 8 位输入(包括任何时钟或复位)和 8 位输出。Tiny Tapeout 使用 OpenLane,这在某种程度上预示着我们也仅限于可综合的 Verilog-2001。
在这个实验的早期阶段,我们对与对话式LLM交互的标准化和(理想情况下)自动化流程的潜力感兴趣,该流程将从规范开始并产生该设计的硬件描述语言。鉴于我们有 8 位输入,我们决定使用其中 3 位来控制设计选择多路复用器,以适应 8 个小型基准测试。如果这些进展顺利,我们就会致力于更雄心勃勃的事情。
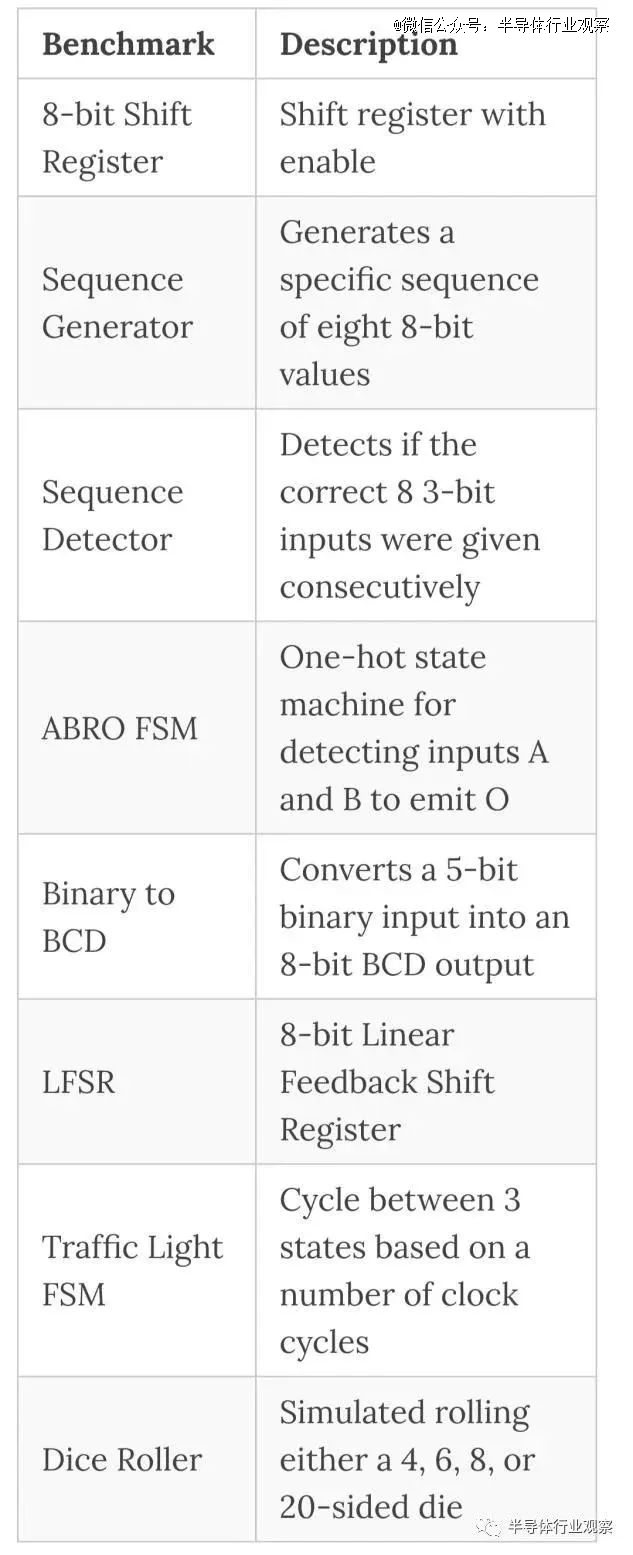
每个基准测试都有一个简短的规范来描述它及其 I/O,以及正确的预期行为。
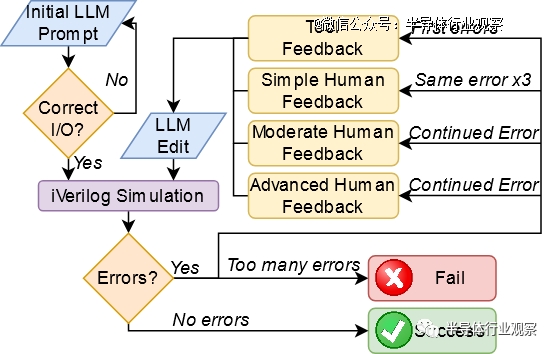
然后,纽约大学博士后Jason Blocklove 与四个选定的LLM(ChatGPT-3.5、ChatGPT-4、Bard 和 HuggingChat)坐在一起,执行前面描述的过程,引导LLM首先生成设计,然后生成测试平台,然后将它们一起模拟,并反馈任何错误。
有时,谈话中需要仔细考虑特殊情况。由于模型在一次响应中能给出的输出量受到限制,文件或解释通常会被中断;在这一些状况下,模型将提示“请继续”。continue 之后的代码通常从较早消息的最后一行之前开始,因此当代码被复制到文件中进行编译和模拟时,它会被编辑以形成一个内聚块。然而,这样的一个过程没有添加额外的 HDL。同样,有时响应中会包含让用户添加自己的代码的注释。如果这些注释会阻止功能,例如留下不完整的值数组,则将重新生成响应,否则将保持原样。

在试过之后,我们得知返回的设计质量参差不齐,我们得知只有 ChatGPT-4 可以可靠地生成设计。以下是每个LLM的*个设计(移位寄存器)的示例:
一旦我们有了设计,我们就必须提示建立一个测试平台,在这里,我们将用以下提示词:
以下是完整的对线.我们先看一下ChatGPT 4.0生成的回复。我们第一步问:
我根据移位寄存器的正确行为更新了测试用例 1、2 和 3 的预期输出。现在,当您运行模拟时,它应该显示“所有测试用例已通过!” 没有一点错误。而事实上,它也确实通过了,没有一点错误!

总体而言,只有 ChatGPT-3.5 和 ChatGPT-4 可以可靠地生成设计,因此我们最终只分析了这两个模型,并将 Bard 和 HuggingChat 从我们的结果中排除。使用两个 OpenAI 模型,我们完成了全套基准测试 3 次,得到了以下结果:
由此可见,ChatGPT-4表现良好。大多数基准测试都通过了,其中大多数只需要工具反馈。ChatGPT-4 在测试平台设计中最需要的人工反馈。
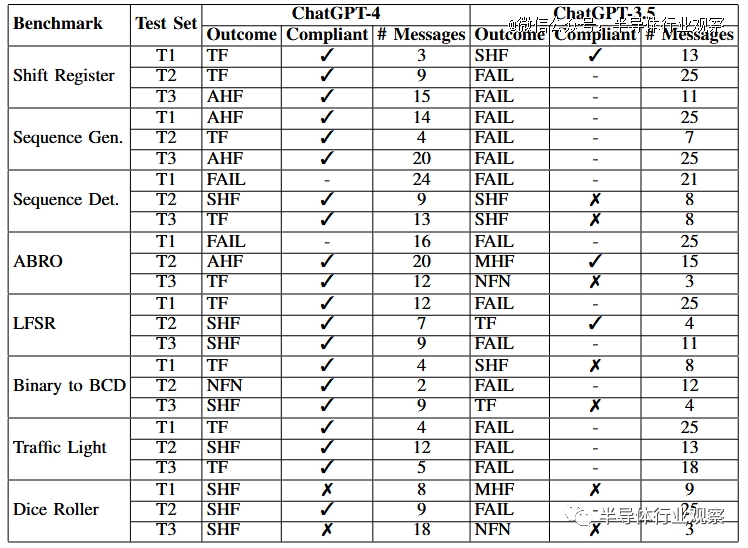
测试集 T1 中的Dice Rollers将在一次roll中输出 2,然后在所有后续roll中仅输出 1,无论选择何种die。同时,Dice Roller T3 会改变值,但仅限于快速重复的一小部分(取决于所选die)之间。为了闭合设计循环,我们从 Tiny Tapeout 3 的 ChatGPT-4 对线,添加了由 ChatGPT-4 设计但未经测试的包装器模块(wrapper module )。整个设计需要 85 个组合逻辑单元、4 个二极管、44 个触发器、39 个缓冲器和 300 个抽头来实现。
ChatGPT-3.5的表现明显比 ChatGPT-4 差,大多数对话都导致基准测试失败,并且大多数通过个人测试平台的对话都是不合规的。ChatGPT-3.5 的故障模式与 ChatGPT-4 相比不太一致,每次对话和基准测试之间都会引入各种各样的问题。与 ChatGPT-4 相比,它需要更频繁地修正设计和测试平台。
只有 ChatGPT-4 能够充分满足编写 Verilog 的目的,尽管它仍然需要人类反馈才能使大多数对话成功并符合给定的规范。修复错误时,ChatGPT-4 常常要多条消息来修复小错误,因为它很难准确理解哪些特定的 Verilog 行会导致 iverilog 发出错误消息。它所添加的错误也往往会在对话之间经常重复出现。
ChatGPT-4 在创建功能测试平台方面也比功能设计付出了更多努力。大多数基准测试几乎不需要对设计本身做修改,而是需要修复测试平台。对于 FSM 来说尤其如此,因为该模型似乎无法创建一个测试平台来正确检查输出,而无需有关状态转换和相应预期输出的重要反馈。另一方面,ChatGPT-3.5 在测试平台和功能设计方面都遇到了困难。
在基准测试期间,我是 ChatGPT-4 的学生,现在我已准备好接受更大的挑战,并着手让它为微控制器创建组件。我想知道非结构化对话是不是能够提高模型的性能水平,使用一种共同的创造力来更快地编写设计。
为什么要进行这种设计而不是 RISC-V 之类的设计?众所周知,ISA 的开源处理器有很多实现,例如 RISC-V 和 MIPS。问题是,这在某种程度上预示着 GPT-4 在训练期间已经看到了这些设计。对于这项工作,我不想简单地探索 ChatGPT-4 发出其训练过的数据的能力。相反,我想看看它在制作更新颖的东西时的表现。因此,我使用 ChatGPT-4 本身提供的奇怪 ISA 来引导模型进行全新的设计,我认为这与开源文献中提供的内容完全不同。
对话线程(Conversation threading:):鉴于 ChatGPT-4 与其他 LLM 一样具有固定大小的上下文窗口,我们假设提示模型的*方法是将较大的设计分解为子任务,每个子任务都有自己的“对话线程”界面。这使总长度保持在 16,000 个字符以下。当长度超过此值时,专有的后端方法会执行某种文本缩减,但其实现的细节很少。
由于 ChatGPT-4 不在线程之间共享信息,人类工程师会将相关信息从前一个线程复制到新的*条消息中,从而形成一个“基本规范”,慢慢地定义处理器。基本规范最终包括 ISA、寄存器列表(累加器ACC、程序计数器PC、指令寄存器IR)、存储体、ALU 和控制单元的定义,以及处理器在每个周期中应执行的操作的高级概述。本规范中的大部分信息由 ChatGPT-4 生成,并由人工复制/粘贴和轻微编辑。
主题(Topics):每个线程一个主题对于处理器的早期设计阶段效果很好(有一个例外,其中 ALU 是在与多周期处理器时钟周期时序计划相同的线程中设计的)。然而,一旦处理器进入模拟阶段并在其上运行程序,我们就发现了规范和实现中的错误和错误。设计工程师没有开始新的对话线程并重建先前的上下文,而是选择在适当的情况下继续先前的对话线程。我们在下面的流程图中对此进行了说明,其中“Cont. T. ID”列指示他们是否“Continued”前一个线程(如果是,则为哪个线程)。
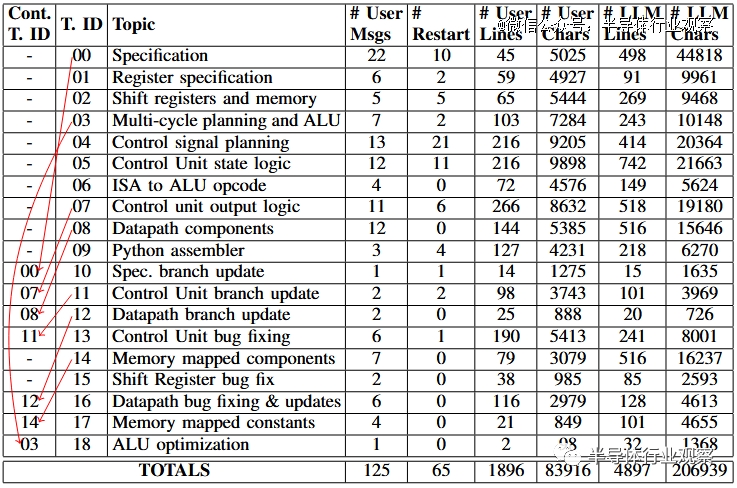
有时 ChatGPT-4 会输出次优响应。如果是这样,工程师有两个选择:(1) 继续对话并推动它修复响应,或者 (2) 使用界面强制 ChatGPT-4“重新再启动”响应,即通过假装先前的结果来重新生成结果答案从未出现。在这些之间做出合理的选择需要权衡并要专业判断:继续对话允许用户指定先前响应的哪些部分是好的或坏的,但重新生成将使整个对话变得更短、更简洁(考虑到有限的上下文窗口,这是有价值的)尺寸)。
尽管如此,从结果表中的“# Restart”列能够准确的看出,随着我使用 ChatGPT-4 的经验越来越丰富,重新再启动的次数趋于减少,与主题 08-18 相比,主题 00-07 的重新再启动次数为 57 次只有 8 次。在主题 04(控制信号规划)中,单条消息的最高个体重启次数为 10,其中包含以下消息:
然后我又说:Unfortunately, it doesnt work if the WIDTH is set to 1. Can you fix it?
现在,“scan_enable”信号比“enable”信号具有更高的优先级。当两个信号都为高电平时,移位寄存器将工作在扫描模式而不是正常模式。同时我们也证明了,这个错误修复也有效!

下表列出了在对线 中与 ChatGPT-4 共同生成的 ISA(并在 10 中更新):
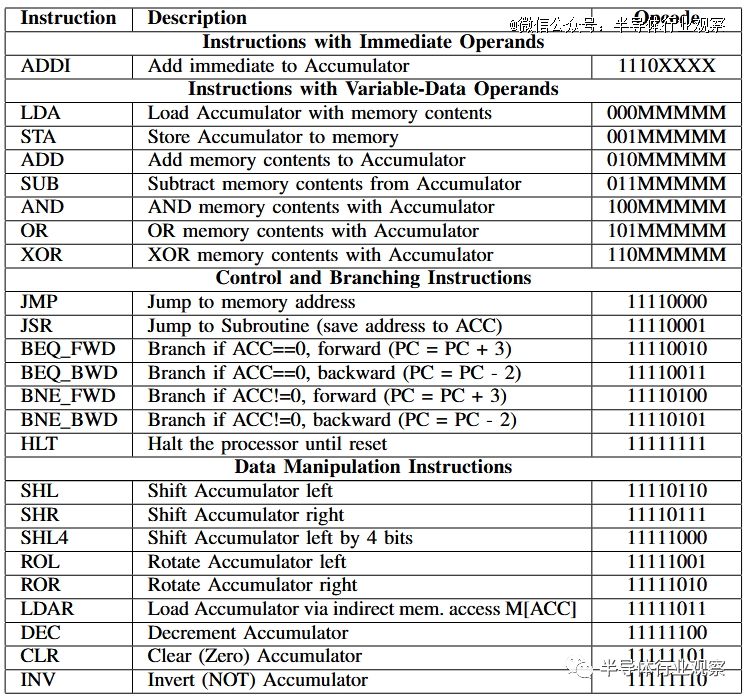
分支指令有限制但很有用。向后跳过两条指令能轻松实现高效轮询(例如加载输入,屏蔽相关位,然后检查是不是为 0)。向前跳过 3 条指令可以跳过 JMP 或 JSR 所需的指令。这些是经过多次迭代设计的,包括后来的修改(对线,“分支更新”),它将向前跳转从 2 条指令增加到 3 条,在模拟过程中我认识到我们没办法轻松地在中编码 JMP/JSR只需 2 条说明。
这是最终产生的数据路径(控制信号用虚线表示 - 使用摩尔型多周期(moore-type multicycle ) FSM 来控制它们)。在设计处理器时,我确保每个寄存器也通过扫描链连接(也是由 ChatGPT-4 设计的!)。这在某种程度上预示着我可以在实现后对设计进行编程,这也是我在模拟期间加载测试程序的方式。
我尝试使用 OpenLane 进行合成,但糟糕的是,该设计不适合 1000 个标准单元(standard cells)!最简单的事情就是不断调整内存,我一遍又一遍地这样做,直到我最终达到了神奇的数字,并设法获得了仅 17 字节的数据和指令内存组合。
我编写了一些测试程序,很快意识到我需要一些重复出现的常量值。玩了之后我还发现,内存映射中的常量值并没有寄存器占用那么多空间!因此,我设法将一些常量辅助值(包括“1”和“0”)放入内存映射中。

在实际测试中,该设计是工作的。所以我很高兴,它在模拟和 FPGA 上都能工作,所以我很高兴地将它发送到 Tiny Tapeout进行流片。

该项目于 2023 年 6 月 2 日上线,并(相对)受到了很多关注!EDA 领域的许多不同公司也与我们联系,这中间还包括一些您肯定听说过的公司。
所以在QTcore-A1上,我们修改了微控制器,以便它能够占用 平台中更大的可用区域(仅使用一个可用空间的一部分)。
尽管这是基于 OpenLane 的,就像 Tiny Tapeout 一样,但它是一个更加手动和复杂的过程,并没一个简单的基于 Github 操作的工作流程。我必须在我的笔记本电脑上安装很多东西!
然后,我决定让 ChatGPT-4 对 QTCore-A1 进行以下更改。首先,内存大小将升级为256字节共享指令/数据内存,分为16字节页面;其次,我会添加一些外设:一个 16 位定时器、一些 I/O 端口,并且考虑到我的日常工作是硬件安全研究员,我还决定添加 2 个八位“内存执行保护”控制寄存器为 16 个页面中的每个页面提供“执行”位,并更新原始的、被诅咒的分支逻辑。
从这个设计能够正常的看到,里面有了很多的变化!例如观察现在有一个段寄存器,它与部分指令连接在一起,以解码具有可变数据操作数的指令的地址。
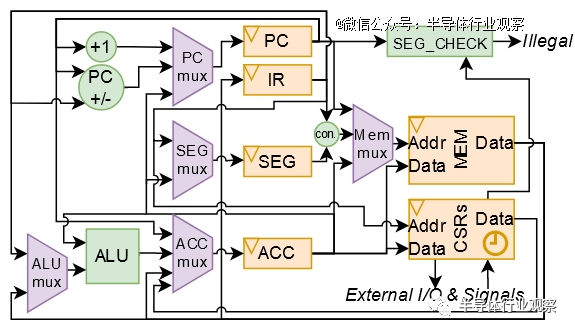
控制单元:用于驱动处理器的2周期FSM(3位one-hot编码状态寄存器)
SEGEXE_L (000):8 位 - 表示指定为可执行文件的内存段的下半部分。寄存器中的每一位对应内存空间下半部分的一个段。如果某个位设置为 1,则相应的段被标记为可执行。
GPT-4 生成的汇编器简化了为 QTCore-C1 编写汇编程序的过程。


我需要测试的*件事是我实际上可以与我的芯片对话,就像我在模拟中所做的那样。我启动了我为原始竞赛截止日期编写的程序,并将其放入 Caravel,然后意识到它仅根据模拟器检查值“通过” - 即处理器实际上没有发出任何东西!因此,我必须更新 RISC-V 程序以支持 UART,幸亏有 caravel 文档,这非常简单。
很难描述在我面前有一块我参与设计的工作硅片是多么令人惊奇,特别是因为我以前从未真正设计过任何流片。如果没有像 ChatGPT 这样的LLM来激励我去尝试,我也许也不会这么做。

